
Quest to determine the 'G' in GUAC
Working towards determining a persistent database for GUAC

Parth Patel
June 27, 2023

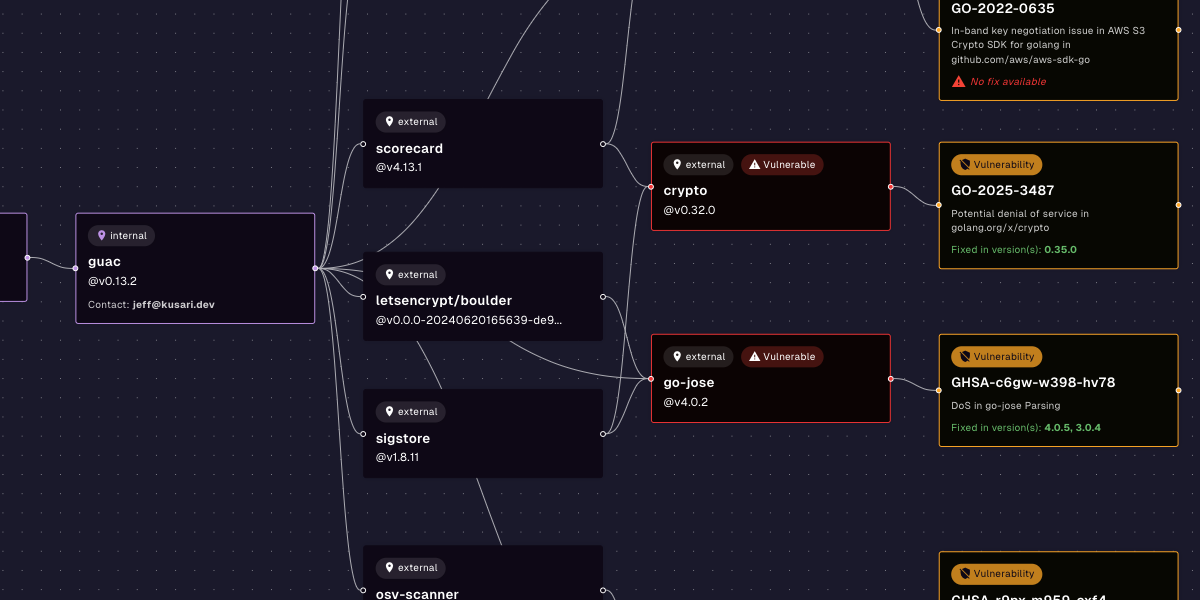
In the era of big data and interconnected systems, organizations face the challenge of effectively managing and analyzing complex relationships within their data. Graph databases have emerged as a powerful solution for representing and querying highly connected data, enabling businesses to gain valuable insights. With GUAC (Graph for Understanding Artifact Composition), we face a similar issue. With large amounts of data from SBOMs, SLSA attestations, and other ITE-6 based attestations, it is integral that we can effectively manage and create the edges that represent the relationships between these documents.
As we work to meet the goals of persistence in GUAC, we are running a series of analyses and comparisons among the many different graph database options. GUAC has a few critically important requirements for the backend, including: efficient ingestion of data, performant complex queries, the schema in which the data is stored, and finally optimization of the query based on the specific language.
Evaluating the Requirements
- Efficient Data Ingestion: A graph database that excels in data ingestion is essential for managing large-scale datasets. The speed and efficiency of data ingestion directly impact the ability to update and integrate new information into the database seamlessly. This is important as software supply chain metadata will constantly be growing. For example, the time it takes to ingest packages and create the dependency relationship between them. In graphQL this would relationship would look like:
- First, we would have to ingest the packages (both package and dependent) and after that ingest the actual dependency node that connects to two packages together. We have to work to reduce the time that it takes complete these series of steps in the most efficient manner.
- Quick and Complex Query Execution: Graph databases provide powerful querying capabilities for traversing complex relationships and uncovering valuable insights. The efficiency of query execution is crucial, especially when dealing with large datasets. For GUAC, being able to answer specific queries quickly can allow for quick and proactive decision-making. While complex queries might still take time that a fast-paced industry leader cannot afford, we can work around this by pre-computing results from these queries and creating “proceed” or “not proceed” type attestations that can be updated based on a set schedule. For example, for GUAC we would want to quickly determine which all the vulnerabilities (even transitive) for a particular package or artifact:
- The query above has to traverse the relationships between the packages and vulnerability information to provide us the output shown above.
- Schema: Data ingestion and retrieval is not just reliant on the database you choose to work with, it also depends on the schema in which the data is stored. A complex schema with unnecessarily fragmented data can result in poor performance for ingestion and querying. Simplifying the schema greatly improves performance by reducing the number of reads and writes that need to take place. In graphQl the schema would look like the following for dependency between two packages:
- The above schema contains the necessary information to create the dependency relationship. We can map this schema or a representation of this, for the graph database to store and retrieve the data needed to recreate the “isDependency” node.
- Optimizing the query language: Many graph databases (such as ArangoDB or Neo4j) come with their own query language that can be used to ingest and read data. Optimizing the query for the most efficient reads and writes can be challenging and may require evaluation/inspection to determine where the costly operations are occurring. For example, a query to ingest dependencies may look like the following in Arango Query Language (AQL) which is quite complex:
- While in neo4j, it would be:
- Both queries are different but are trying to achieve the same operations, ingestion of the “isDependency” node. For each language, the query must have efficient traversal, proper indexing and limit the number of nodes that have to be filtered. We also need to remove unnecessary “UPSERT” or “MERGE” which either “INSERT” or “UPDATE” depending on the node which can be costly operations. These queries have to be carefully crafted for each language utilizing their own unique syntax.
Quantitative Analysis
As we work towards providing a persistent database for GUAC, the above characteristics need to be measured and quantified. Currently, we are in the process of evaluating ArangoDB, Neo4J and Cloud Spanner. The GUAC community is also evaluating AWS Neptune and ENT (an ORM framework that supports multiple backends such as SQLite, MySQL, and others). The flexibility of GUAC, via its graphQL interface, is that we are not limited to a singular database. We have the ability to support multiple depending on the use cases but maintenance can be troublesome. Therefore, we must do our due diligence to determine which databases should be incorporated as the persistent backend for GUAC. Stay tuned for our next blog where we go into further detail about the evaluations of the above characteristics in the databases we mentioned above. We will go into specific details and provide real word metrics around ingestion and execution times.
To learn more about GUAC, visit the official site at https://guac.sh, the docs at https://docs.guac.sh, or the source code repository at https://github.com/guacsec/guac (Give us a star while you’re there!).
Like what you read? Share it with others.














.webp)








.webp)






















.png)
.png)




.png)
.png)
.png)
.png)
.png)
.png)
.png)



.png)









.jpg)





































Previous
No older posts
Next
No newer posts
Want to learn more about Kusari?