
Applying Zero Trust to the Software Supply Chain
Understanding Zero Trust and Its Benefits

Michael Lieberman
March 28, 2023
.webp)
In a previous article, we went over a high-level overview of what software supply chain security is and how it can be solved. We explored the complex world of software supply chain security, highlighting the importance of SDLC security and the key areas that must be protected. We discussed the potential impact of supply chain attacks and vulnerabilities, emphasizing the need for comprehensive and holistic security measures. Building on this foundation, this article delves into how the zero trust model and identities can be applied to software artifacts to enhance supply chain security. By incorporating zero trust principles, organizations can better safeguard their software supply chain, ensuring granular access control, limited blast radius, and improved visibility across the entire SDLC.
Understanding Zero Trust and Its Benefits
We won’t go over the details of zero trust security in this article. There are already many great resources out there that explain it much better than I can. However, let’s go over some of the principles, practices and benefits of applying zero trust generally and then see how we apply those same principles specifically to the software supply chain to achieve similar benefits there.
A core concept of zero trust is “never trust, always verify.” Simply put, don’t assume someone that is in your network is trusted to perform any action. You must verify that they are supposed to be there and that they are allowed to do what they’re attempting to do. Let’s look at an example.
An Example
Alice is a software engineer at ACME. If ACME’s networks don’t follow zero trust and the concept of “never trust, always verify” a successful cyberattack might look like this:
- The attacker steals Alice’s credentials
- The attacker logs into ACME’s networks, impersonating Alice’s identity.
- The attacker gets access to any system that Alice is authorized to access. This includes the data on those systems.
Now let’s look at that same attack when following the concept of “never trust, always verify.”
- The attacker steals Alice’s credentials
- The attacker attempts to log in to ACME’s systems but is blocked because they also don’t have Alice’s workstation, and they are logging in from an unapproved location.
Even though an attacker could steal Alice’s credentials and attempt to log in they wouldn’t get very far. Even if an attacker wasn’t blocked at log in, every action the attacker attempts to do would be verified against the organization’s security rules. A benefit of zero trust security is the blast radius of a compromise is smaller. In zero trust, it is difficult for an attacker to use the compromise of one user’s credentials or one system to compromise other systems and users.
Zero Trust Practices
Building on top of “never trust, always verify” zero trust security leads to a shift from network perimeter-based security to a data-centric approach. Don’t assume that someone who has access to a system within the network should have access to all the data in that system. In the previous example with Alice, in a non-zero trust network, the attacker would often get access to data just because Alice has access to the system the data lives on. In a zero trust network, even if the attacker was successful in compromising a system, they would only get access specifically to data that Alice is allowed to access based on security rules and policy.
This leads us to a key set of practices in zero trust networks. The organization applies various practices like least privilege, data classification, continuous monitoring, and context-aware access controls to implement a zero trust network. This is not an exhaustive set of zero trust practices but some important ones that will also apply to the supply chain:
- Least privilege - Alice is only given access to what she needs to perform her job. Nothing more. This lessens the impact in the case of Alice’s credentials being compromised.
- Data classification - By classifying the data in ACME, they can provide users like Alice with only the data they need to limit what is exposed in the case of a breach.
- Continuous monitoring - Continuously verifying the actions that Alice is performing against the security rules of the network allows ACME to catch anything suspicious as it’s happening while also having an audit trail.
- Context-aware access controls - Adding contextual information like time of day and location to access requests ACME can catch suspicious activity like someone using Alice’s credentials logging in from other countries at times she’s not usually working.
A common thread that ties these practices together is the need for systems and controls around identity. Identity is used as the basis for authenticating users, devices, and systems. It is used to determine what users, devices, and systems are authorized to perform what actions within the network. Furthermore, it’s used to better log and audit what users, devices, and systems are interacting with each other and how.
By applying various practices to implement a zero trust network, an organization like ACME can better protect its data and other assets. It also becomes easier to protect these assets by enabling granular access control, limiting blast radius in the case of a breach, and providing visibility into the interactions in your network for the detection of suspicious activity and audit.
Applying Identity to the Supply Chain
Now let’s take these principles and practices and start applying them to the software supply chain. The focus on zero trust is usually applying the concept of “never trust, always verify” to devices and users but we can extend that further to software and its dependencies. By applying this concept and following similar zero trust security practices for the SDLC we can see similar benefits to what we see when applying zero trust practices to users and devices.
In the last article, we looked at what we wanted to protect in the SDLC. To refresh:
- Developer
- Workstation
- Development Environments
- Source Control
- Build System
- Artifact Repository
- Production Environments
We want to protect these assets from attacks, in particular software supply chain attacks. Software supply chain attacks manifest themselves by compromising anything that touches the source code, dependencies, or compiled/packaged artifacts in the SDLC. It starts with the developer writing code and ends with their code running in production as a built software artifact.
Associating Identity
How can we start applying zero trust to things like source code, dependencies, and compiled/packaged artifacts along with the things that touch them to better protect our supply chain? First, we need to associate identities with these things. Similar to zero trust as applied to users, devices, and systems, we need to have mechanisms to manage and verify elements within our software supply chain.
For users, you often user record in an LDAP server along with associated credentials. For a device, this is a record in some sort of device management database often with an associated certificate. For systems, we often have configuration management databases (CMDB) and similar tools. For software, there are a few options. We can use things like CMDBs, but they aren’t comprehensive. Since so much software comes externally, often through open source, we have no way of asserting the identity of where the software came from securely.
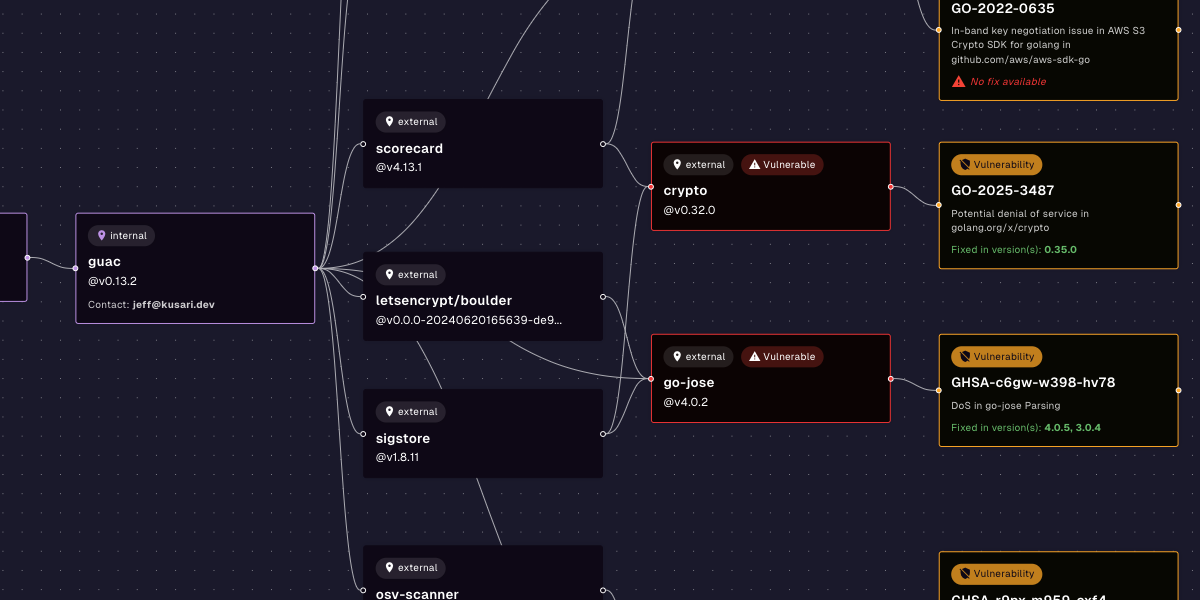
This is where signing and attestations come in. Traditionally signing has been done via tools like GPG allowing an organization or developer to sign the software artifacts, source code, etc. they provide and then they can distribute their public key(s) to the community so that consumers of their software can verify that the software did come from the provider you expect. This is a start, but it can be quite difficult to manage the distribution of keys, signatures, etc. Luckily there are newer toolsets like Sigstore that have begun to evolve the space. Sigstore allows for associating signatures with external identities like a developer’s Github account or an organization’s Google identity.
Attestations on the other hand are just signed metadata documents with claims about the software in them. These are usually claims like software was built in a specific way or assertions about vulnerabilities within that software. This allows us to have rich information about software, source code, and their dependencies associated with various identities. These identities could be the software provider, a third-party security firm, an audit firm, etc.
Associating identity and important metadata to artifacts are the first steps to take in implementing zero trust for the supply chain. Without associating identities with software, other practices like implementing least privilege and context-aware access controls become difficult or impossible. There’s just not enough data to base decisions on. As we continue to explore zero trust we’ll look at how associating metadata and identity with artifacts will help us achieve our goals of software supply chain security. We’ll also begin to publish some real implementation examples using tools and frameworks like GUAC, Sigstore, SLSA, and FRSCA.
Until then, we’d love to hear from you about how you’re looking at associating identities with the software you develop and consume. Are you currently signing and attesting your software? Are you asking your external software providers to sign and attest their software?
Like what you read? Share it with others.























.webp)






















.png)
.png)




.png)
.png)
.png)
.png)
.png)
.png)
.png)



.png)









.jpg)





































Previous
No older posts
Next
No newer posts
Want to learn more about Kusari?